Binary Classification with a Bank Churn
Sep 18, 2024
Overview
Today is the seventh day of 30 Kaggle Challenges in 30 Days. I took a day off after six days of continuous posting. Solving the problems, writing the blog, and posting it takes a lot of time. Additional time is also consumed because the website is new, and almost daily, I discover some bugs, which also take my time. Going at this pace and considering my other commitments, I think this challenge will take more than 30 days, maybe it will take 36 days.
Problem Description
Today’s problem is binary classification with a bank churn dataset. The task is to predict whether a customer continues with their account or closes it (e.g., churns). The evaluation metric is the area under the ROC Curve between the predicted probability and the observed target. The dataset for this competition was generated from a deep learning model trained on the bank customer churn prediction dataset. Links for both are as follows:
Kaggle Dataset: Season 4, Episode 1
Original Dataset: Bank Customer Churn Prediction
Data Description
The training dataset has 14 columns: two for IDs, one for the target variable ‘Exited’, and 11 for features. The sizes of each dataset are as follows:
Train Shape: Rows: 165034 Columns: 14
Test Shape: Rows: 110023 Columns: 13
Target Distribution
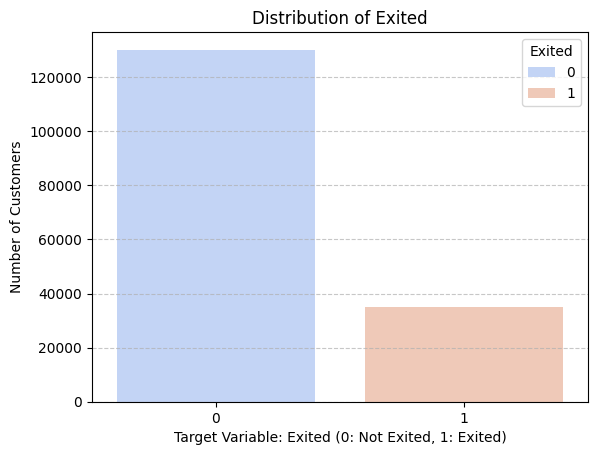
The difference between the two values makes the dataset highly imbalanced. We will use stratified folds to validate the model performance, which will reduce the impact of imbalanced data.
Model Performance
I have fitted the following models and ran each on five-folds I created from the training dataset. The average score of each are as follows:
| Model | Average AUC | Average Time (sec) |
|---|---|---|
| LightGBM | 0.8893 | 0.652 |
| Gradient Boosting | 0.8885 | 22.12 |
| CatBoost | 0.8885 | 15.292 |
| XGBoost | 0.8863 | 0.682 |
| AdaBoost (SAMME.R) | 0.8803 | 6.376 |
| AdaBoost (SAMME) | 0.8735 | 5.536 |
| Logistic Regression | 0.8707 | 0.394 |
| Random Forest | 0.8705 | 16.806 |
| Extra Trees | 0.8572 | 14.394 |
| Bagging | 0.8422 | 6.86 |
| K-Nearest Neighbors | 0.8177 | 3.58 |
| Decision Tree | 0.7022 | 1.128 |
Table: Average AUC Score and Average Training Time per Model
I got the best score by using the LightGBM model.
Result
I have finalized the LightGBM model for final submission.
Kaggle Score: 0.89197
Progress on Challenge
This challenge is taking up all of my time. I barely do anything else than solve Kaggle’s problems. The first 5 days were fun, but now it’s getting repetitive, and the format is fixed. I think now I should up my game, and instead of just reporting on scores achieved and results of submission, I should try to explore certain parts of the code and explain the logic behind it and the reason for doing that certain task in a certain way. The problem with the Kaggle competition is that I spend a lot of time on hyperparameter tuning and feature engineering instead of learning new models. The internal functioning and algorithm of each model. So, from tomorrow onward, I won’t try to improve the score but to understand why specific models are working and why others are getting low scores.
Links
Notebook: Kaggle Notebook for S4E1
Code: GitHub Repository for Day 7